
使用 Perf 优化程序性能
Jun 16, 2018 · Comments因为原定deepin 15.7会做优化(能耗、资源占用等)方面的工作,所以在此之前,想提升一下团队整体的性能剖析、优化方面的水平,也就有了这次(周五)的培训。本来想用视频记录的,一个是自己回头能看看,反思和改进一下演说能力;另一个是以后有新人入职,我也就不用挨个再讲一遍,天不遂人愿,录制视频的软件半道挂了( 所以只能这里尽量回忆当时想表述的内容,这里文字稿记录了。
下面就是培训内容:
好,人到齐了我们就开始了。今天要培训或者说要分享的内容是程序性能优化方面的内容,其实我们对性能优化不陌生:最开始接触龙芯和申威平台,系统组件间调用不是异步导致系统卡得无法使用;好不容易交了一个版本,控制中心各个模块还是因为切换卡顿、使用体验不好等做改进;前段时间为2G内存机器做优化等等。现在我们因为程序设计问题导致的性能问题比以前少了很多,一方面我们还要对这些部分持续改进,另一方面我们需要掌握一些性能剖析工具的使用,来帮助我们改进一些更细粒度的程序性能问题,今天我们主要集中在程序执行性能、也就是CPU占用这部分的性能优化。
今天培训的内容比较基础,还是老规矩,我做敲门砖,其余的还需要各位发挥。

刚才说了我们以前做了几次优化,我们再来回顾一下为什么要做性能优化。第一点肯定是占用过多的系统资源,不论是CPU、内存还是IO,如果系统组件的资源占用比较高,那系统资源有限、程序间的资源又是会互相竞争的,必定导致用户使用的应用程序的可用资源减少,在一些配置普通的机器上,可能就会导致第二个问题,也就是系统使用不够流畅,当然导致系统使用不流畅也分两部分原因,一个就是我们刚才说的,系统组件占用资源过多,另外一个也是刚才提过的程序架构设计有问题,导致卡界面等等;
第三个是性能问题在低配置的机器上会被无限放大,就像我们在最初的龙芯和申威平台一样,在x86上可能感受不到或者感受不太强烈的问题,在龙芯和申威上就会严重到无法使用(当然,现在的龙芯和申威平台使用已经没有问题了);最后一个也是跟我们15.7想要解决的能耗问题息息相关,就是能耗高、发热大。主要是我们有些系统组件“不老实”,很多情况下随机“抽风”。

这个问题我们论坛用户提到的也不在少数:


当然了,大家可能也知道功耗主要跟系统配置关系很大,例如CPU开不开睿频、有没有设置节能模式,各个网卡、声卡驱动有没有设置节能模式等等,但是我觉得至少我们的程序至少不能成为能耗高的帮凶吧。
现在的情况是我们的程序不仅是帮凶,而且帮得很厉害,一会儿会给大家看一下。

刚才说了我们做了很多次性能优化,可能很多用户期待说我们能一次解决所有性能问题,但是实际上性能优化是持久战,它是一个需要持续做下去的事情。
另外主要还是因为性能优化很难,第一点主要就是性能瓶颈的定位很难,比如最开始我们系统登录的过程非常慢,所有程序都是并行启动,看着所有的系统资源占用都很高,换成串行启动以后,依然如此,这个定位当时就比较麻烦; 第二点是有时候优化的效果并不明显,虽然说我们看到有时候系统的资源占用挺高,但是可能分到每个程序中就不是特别多,做性能优化得慢慢抠,可能从单个程序来看效果并不明显;第三点是有时候做性能优化的技术和经验要求比较高,一方面是性能剖析工具的使用、对程序运行的本质要熟悉,另一方面就是要对被优化程序的代码要非常了解,不然就会导致我们说的第四个问题:优化可能影响正常功能。比如我上次给Dock提交了一个性能优化的提交,虽然有让sbw同学审核代码,但是最后还是导致了一个功能性bug。

虽说性能优化很难,但是……不积跬步无以至千里。所有复杂的系统都不是一天两天做好的,比如我们的桌面环境,到现在经过了四个版本,基本上就是四代人的心血堆积,才做成现在这个样子。
我们每个人都能做好自己那部分的话,众人拾材火焰高,解决系统性能问题我觉得没有那么麻烦,这其实也是为什么我这么迫切要组织这次培训/分享的原因,还是希望我做好敲门砖,像去年做高分屏支持一样,虽然是我开的头,但是其实最后基本上每个都比我做得好,最后我们做高分屏的效果也非常不错。

刚才说了性能优化很难,大家也不要害怕,其实性能优化也没有想象的那么复杂。
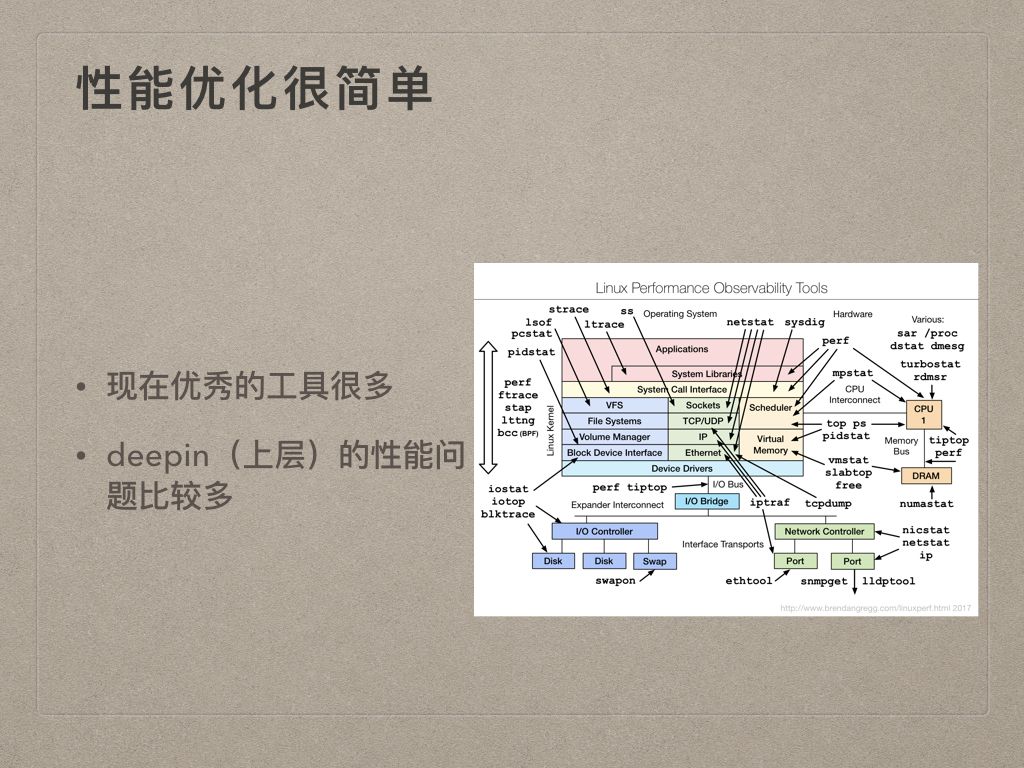
第一个是因为现在优秀的工具很多,比如右边这个非常出名的图,来自 Brendan Gregg 大神的博客。把系统性能优化每个部分对应的工具都清楚的标出来了。
第二个说实话是因为deepin的性能问题还比较多,比较容易发现,相应的上层的性能问题也多,所以说性能优化简单也是因为我们这次主要将注意力集中在 Applications & System Libaraies & System Call Interface这三部分即可。这部分的工具可以看到其实就是 perf、ltrace、strace这些,最多加上 bpfcc 、eBPF等。
说deepin性能问题还比较多是大家可以看到,静置状态下,我什么都不操作,几个组件就又可能时不时抽风一下(占用CPU部分)。
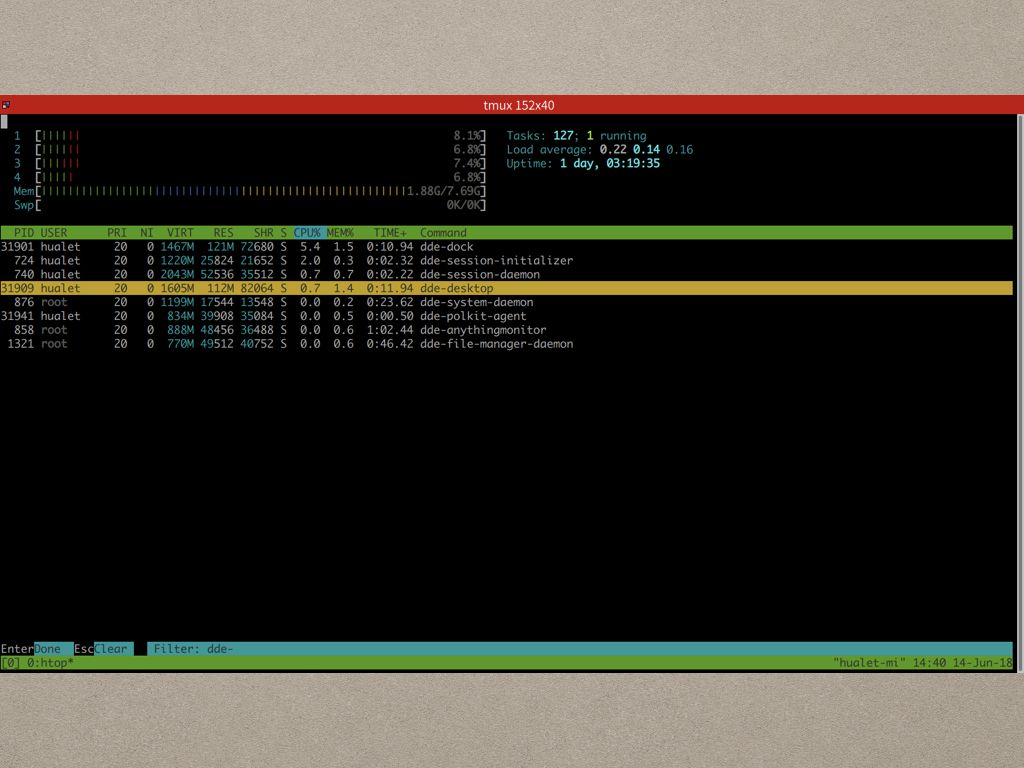
看到了有性能问题,但是我们总得有办法把这些性能问题优化掉吧。
性能优化一般分三个部分,第一部分就是查找程序性能热点,实际上一般我需要先定位性能瓶颈到底是在哪部分,是CPU?是内存还是IO等。不过我们这里目标很明确就是优化CPU占用,所以可以直接朝着有性能问题的程序去。
第二步是热点诊断和修复,找到了性能热点,我们肯定需要修复吧,看看导致这个热点的原因,正常进行修复即可。
第三步是回归测试,就像我们平常修bug一样,修了bug要测试,做了性能优化也一样,我们需要做回归测试、对比一下前后的性能数据。

我们先来看第一步,利用perf查找程序性能热点,这也是我们今天要说得重点。
perf这个工具最开始是作为Performance Counter的接口引入内核的,但是慢慢引入了一堆调试接口如 tracepoint、kprobe、uprobe等等,也就慢慢发展成为Linux几乎最好用的性能调试工具了。
我们平常使用的perf命令是用户态的工具,前面说得那些都是内核里面做的事情,内核态工具主要是对搜集到的数据和事件进行处理和统计。因为这个工具跟内核版本关系比较紧密,所以安装perf的时候需要注意跟内核版本对应的问题。当然,调试的时候装dbgsym包是必须的。
使用perf查找程序性能热点,一般主要用到三个子命令,第一个就是 perf top,这个很好理解,top命令大家都用过,那个top主要是针对进程或者线程级别的资源占用进行统计和展示,perf top可以理解为函数级别的top,可以动态展示系统目前占用资源最高的函数分布情况,它后面的 -g 是启用函数栈,-p 后面加上进程 PID就可以针对单个进程进行追踪,这个跟top命令一致,如果不加 -p 就是默认系统级的统计和展示。
第二个命令是 perf record,它跟第三个命令 perf report 是搭配使用的,record 用来记录一段时间内的程序执行情况,然后用 report 来进行展示。 -g 参数的意义跟 perf top一致,启用了函数栈以后,我们可以使用 –call-graph 来制定使用哪种方式来获取函数栈:
fp 方式,是使用传统的方式 frame pointer来获取堆栈,这个我在之前的文章中也介绍过;
dwarf 方式,是利用dwarf中的信息,应该主要是 .eh_frame 中的信息进行堆栈回溯;
lbr 方式,是利用了Intel新的CPU中的LBR相关的寄存器来获取堆栈信息,LBR和Performance Counter都是Intel为了方便做profiling 和 tunning加的额外寄存器。
这三种方式中我自己使用的过程中主要还是用 dwarf 方式,第一种方式有时候不是特别靠谱。(第三种方式生成的perf.data无法被hotspot解析)。
-F 是指定采样的频率。这里插一句,性能优化相关的三种类型的工具,一种是sampling类型的,即采样,这种工具就是不停“询问”程序在做什么,perf在我们使用的这种模式下就是 sampling模式,如果是追踪某些event,就工作在trace模式,实际上就是第二种类型的工具,这种工具主要依靠事件或者hook,程序在运行的过程中不停主动告诉工具它自己在做什么,比如 strace;第三种是 instrument 类型的,这种主要就是依赖编译器进行插桩,精确知道代码行级别的执行情况(参考gcc instrumentation )。言归正传,这里 -F 99就是每秒采样99次。
一样地,perf record 可以加 -p 表示跟踪单个进程,也可以不加表示跟踪整个系统。


perf record记录程序运行数据,会在当前目录生成 perf.data文件,这个文件可以用 perf report来进行解析和展示,它也是默认读取的当前目录下的 perf.data。
(演示 perf report 展示的样子)
–stdio 参数可以让 perf report 标准输出进行展示,这个我比较喜欢,总觉得比 tui 的模式一个一个站看看要方便很多。 –no-children 是以自底向上的模式真是统计数据,这里需要说明一下的是,一般profiler最终展示堆栈统计数据,都会提供两种模式,一种叫 TopDown,就是从调用栈的根(C/C++一般就是 _start -> __libc_start_main -> main)从上至下进行分解,每个函数分支占用了多少资源占用比例;另外一种就是 BottomUp,这种方式下profiler会挑选各个占用资源最多的叶子函数,这里叶子的意思就是它没有子函数调用了。 –no-children就是后面这种方式,不过个人感觉还是 TopDown 的方式比较直观,能从宏观上进行把控,BottomUp 直接掉进细节里面去了,这种方式对付简单的程序还好,但是复杂的系统就比较麻烦了。

下面我们看个例子,首先就拿Dock开刀吧:

启动 perf record 的方式刚才也说了,非常简单,就是这条命令。
如果你的程序CPU占用稳定高的话,这种情况最好定位,直接开始记录即可。不过这里我们想看看到底为什么Dock会偶尔抽风,所以我们可以用htop或者top观察 dde-dock 的CPU占用情况,尽量能把症状出现时候的情况近路进去。
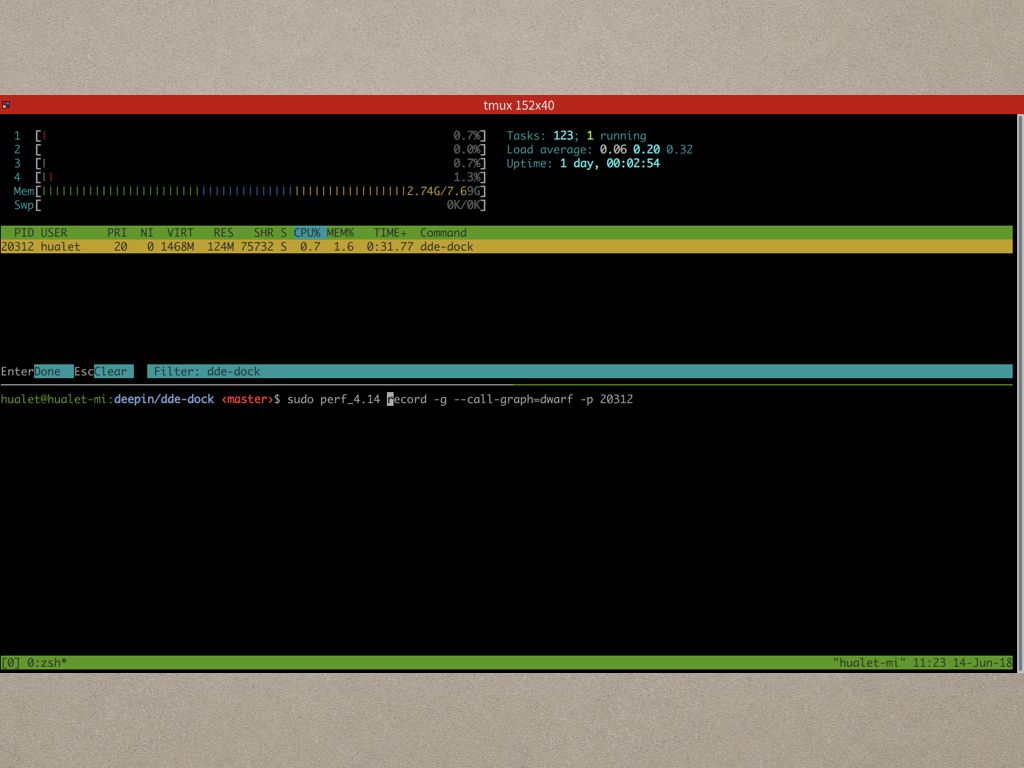
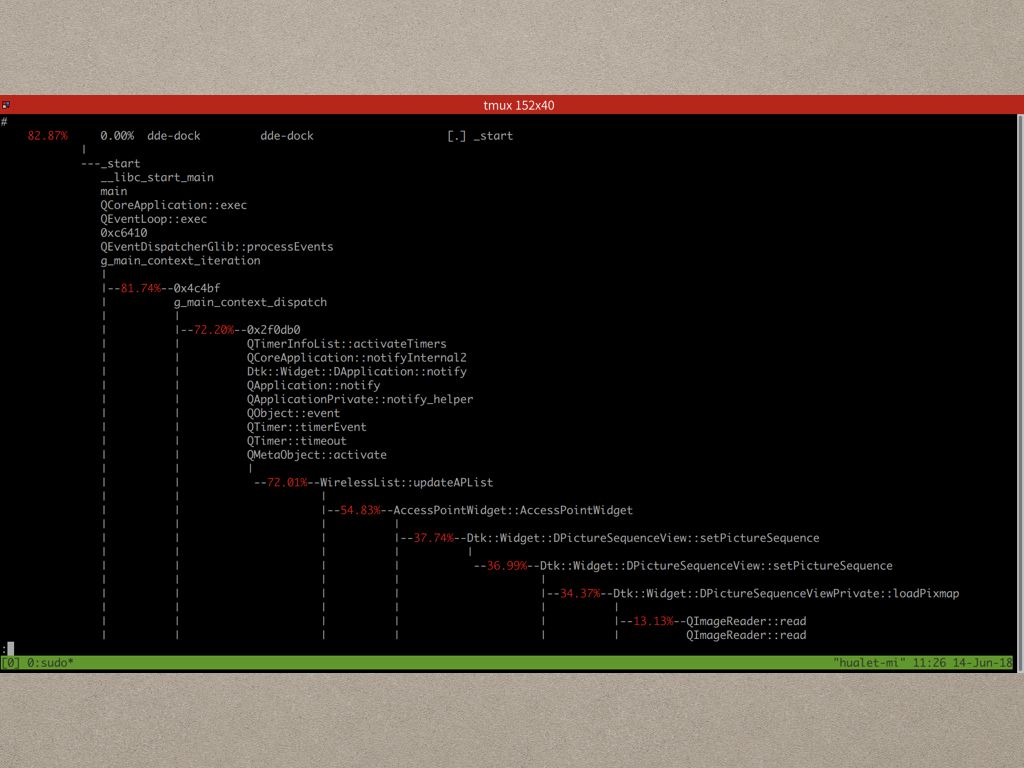
采样并不是每次都非常准确(demo的过程中就有一次取样失败,看不到热点)。
这次的取样就比较完美,热点非常明显,整个热点的分支最终指向了 WireList::updateAPList,不过这个时候我们不太好断定究竟是这个函数执行的次数太多了,还是这个函数本身的占用就非常高(补充:实际上perf report可以使用-n在tui模式下显示函数被采样的次数,如果次数很少的话基本上就是函数实现有问题,但是如果采样次数很多,那就得看看为什么这个函数被调用了这么多次了,得从更上层去分析)。
Dock这个例子看采样数非常少,通过查看 https://github.com/linuxdeepin/dde-dock/blob/4.6.6/plugins/network/item/applet/wirelessapplet.cpp#L232 和 https://github.com/linuxdeepin/dde-dock/blob/4.6.6/plugins/network/item/applet/accesspointwidget.cpp#L32 两部分的代码,可以很清楚的看到问题出在:
- 一个AccessPointWidget 的列表在这个函数里面进行销毁和创建;
- 每个 AccessPointWidget 都包含了一个“臭名昭著”的 DPictureSequenceView ,它每次要加载一百多张图片序列;
所以问题修复可以考虑,
- 重复利用 AccessPointWidget;
- 把 DPictureSequenceView 需要加载的图片缓存,或者使用 QSharedData 进行共享。
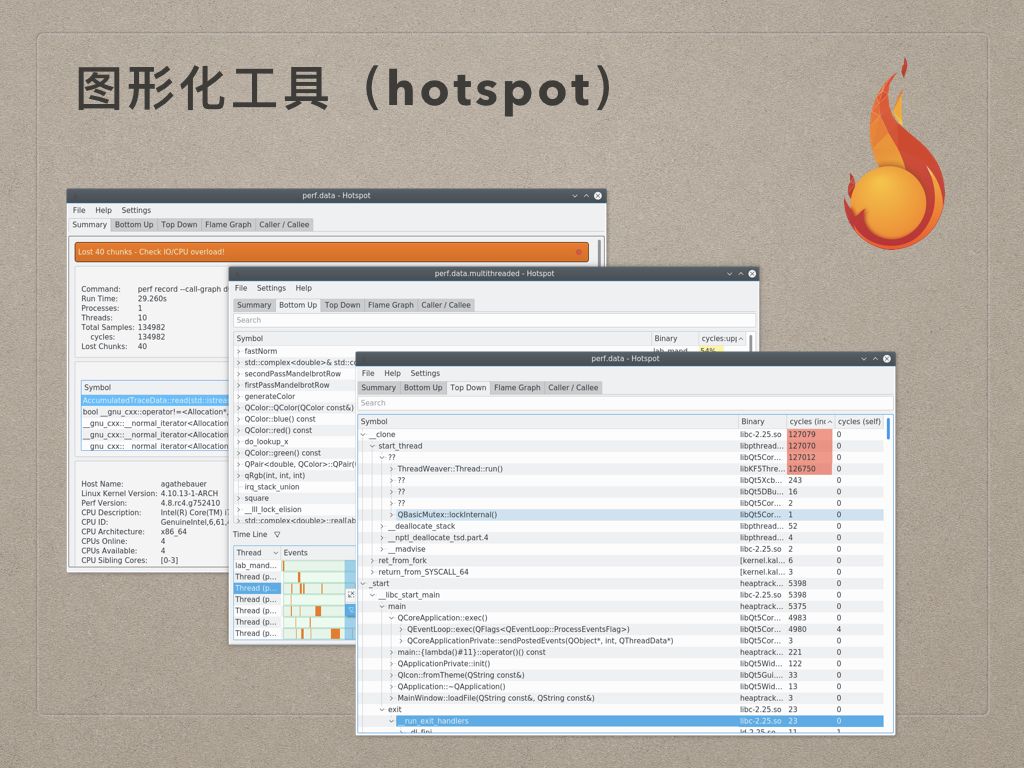
刚才其实宋小哥也说了这种形式的展示方式不是特别好,那么有没有图形化工具呢?答案是有的,这个工具就是 hotspot 。
hotspot 提供了几个比较重要的界面:
- Summary 显示记录数据的一些统计汇总信息;
- Bottom Up 就是刚才说的 BottomUp 的形式展示函数堆栈统计数据;
- Top Down 则是以 TopDown 的形式展示;
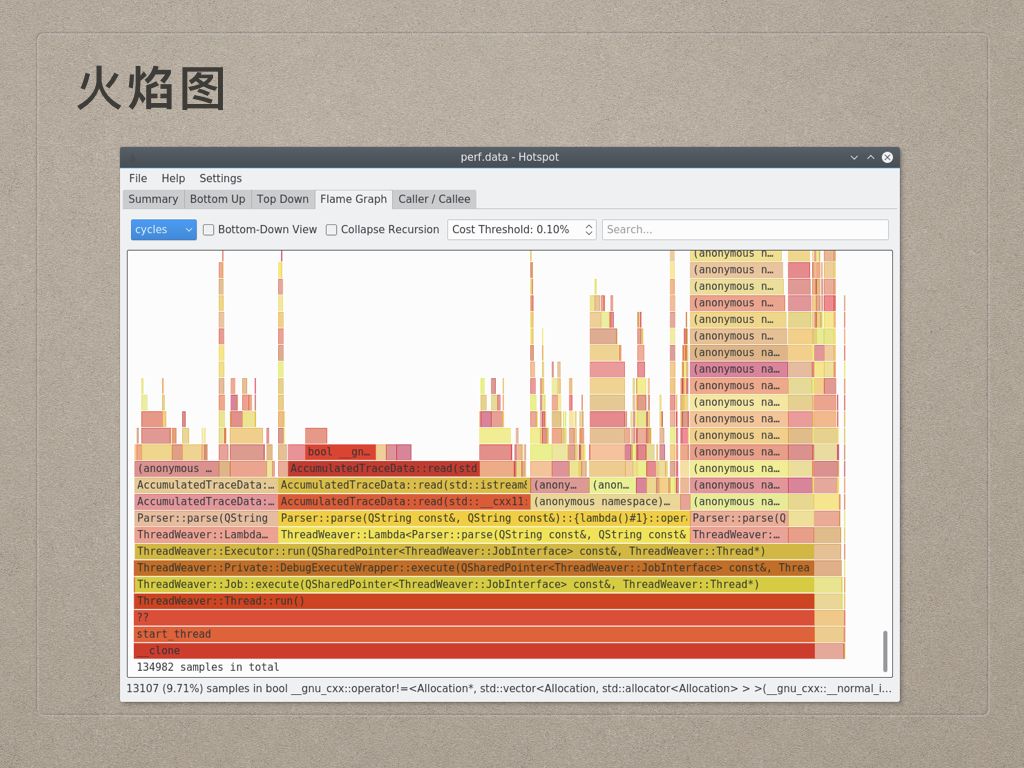
当然,最重要的是,hotspot还提供了方便的火焰图展示。
火焰图这个工具在性能优化领域几乎是无人不知无人不晓的,它以非常直观的形式把函数执行统计情况进行了展示,非常有助于性能热点的发现。不过火焰图很坑人的地方在于,它会产生几个误导,我当时就被误导了。
一个是它的横轴并不跟时间挂钩,我每次都把它当成资源管理器的曲线一样,横轴是时间轴,但是实际上它的横轴只代表比例,即宽度越宽,对应的函数贡献的性能问题越多。
第二个是它的纵轴并不代表资源占用程度,跟上面一样,也是跟资源管理器的曲线搞混了。它的纵轴只是代表了函数堆栈的深度,纵轴越高,代表函数的调用栈越深。
第三个是它的那些颜色没有什么特殊的含义,并不是哪个地方颜色深就是哪个地方是热点。热点存在的地方是那些矮平的地方,因为它既没有子程序调用,占用了很多资源。
(用hotspot看刚才Dock的数据)
定位了性能热点,第二步就是我们说的“热点诊断和修复”了。
虽说第一步很重要,但是第二步才是我们实际修复性能问题的步骤,这个步骤我们首先要注意的是考虑优化性能的时候不要导致功能出错,这个跟代码重构其实是一样的,实际上性能优化就是重构代码,让代码的性能提升。为了避免这种问题,就需要我们进行代码审核了。
这当中也有一个矛盾的地方,就是我们第二和第三点要说的,就是越上层的优化效果越明显,风险相应会提升;越下层的优化风险越小,相对来说效果也越不明显;这里的上层和下层不是火焰图中的上和下,上层是指接近“大逻辑”的地方,就是函数堆栈中靠近根的地方。这个就跟我们平时看到一个bug很多的函数或者功能的时候,我们很可能会选择重写的道理是一样的,设计变动了能解决很多问题,但是风险也是存在的:会不会引入更多问题?
最后要说的一点是优化的方式有千千万万,要因程序、因环境指宜;考虑一个极端的情况,有时候可能性能本身就是跟需求相悖的,这个时候就需要跟产品经理商量如果去做取舍了。

如果觉得自己跟产品打交到不是那么有自信的话,我这里有本书送给大家。(开玩笑)

性能问题可能有很多,不过我们代码里面无非就是下面几个:
- 刚才Dock的例子我们刚好看到是有些比较短小的函数存在问题,那么这个时候我们可以很清楚的知道问题在哪,但是如果我们最终找到的函数实现非常长,不容易找到问题根结的话,我们就需要用最土但是也是最有效的方式:屏蔽一部分代码了;
- 我们以前吃过的大亏就是前后端通信没有异步,这个没什么好说的。另外,因为一些Linux驱动或者基础软件有问题,导致事件驱动的功能有时候不生效,我们很多为了功能正常选择了去轮询,最好我们去掉轮询的代码,如果像这样去不掉,那么就看看能不能加大轮询间隔了;
- 缓存高频数据,我们刚才Dock 的例子就是这样,如果需要加载的那些图片用到很多,其实可以缓存起来;毕竟性能问题多数能靠缓存解决的,一级缓存解决不了的,就来两级;
- 这个比较靠底层,我们目前接触的不是太多,就是避免过多的系统调用,因为系统调用的上下文切换是非常好资源的;另外,像Gtk的icon theme缓存一样,直接使用 mmap 映射到内存里面可以非常高效,这个时候换成使用read调用去读区每个文件的话,哪种低效程度就难以想象了;
- 跟 2 比较像,比较好理解。
- 数据量大的时候,没办法,只能硬碰硬去优化算法了;
- 最后就是减少所的占用时间或者用原子访问了,比如有些互斥锁,宋小哥当时有换成读写锁,这种对于读比较多的系统,就是非常有效的优化了。

好,又说了一大堆,我们再来看另外一个例子:

开始记录的方式跟Dock一样,因为桌面抽风的概率比Dock高,应该很容易能抓到我们想要的数据。
用 perf report 展示出来,看到热点也是比较集中的,就在 CanvasGrindView::paintEvent 这个函数。
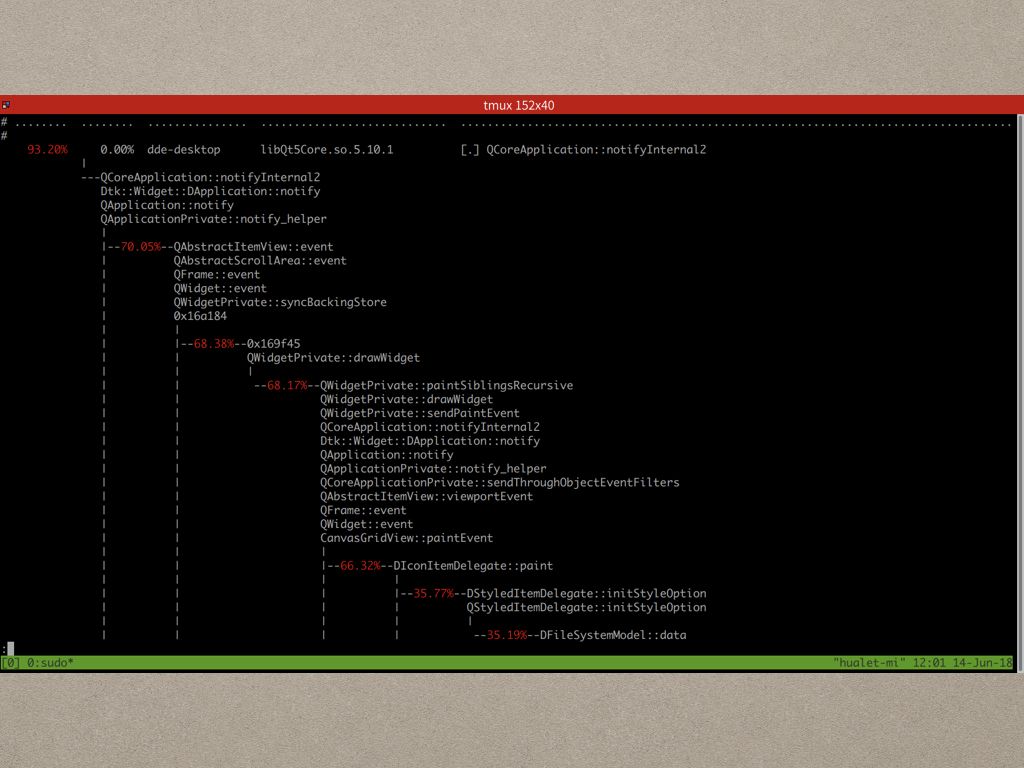
paintEvent的函数栈比较奇怪,实际上比较熟悉Qt代码的知道paintEvent的调用栈中的函数都是Qt事件处理中的函数,根据经验我们知道是通过update发出事件通知Widget更新的,所以我们可以搜一下update函数:通过在https://github.com/linuxdeepin/dde-file-manager/blob/4.5.5/dde-desktop/view/canvasgridview.cpp 这个文件里面搜索,发现update函数调用太多……
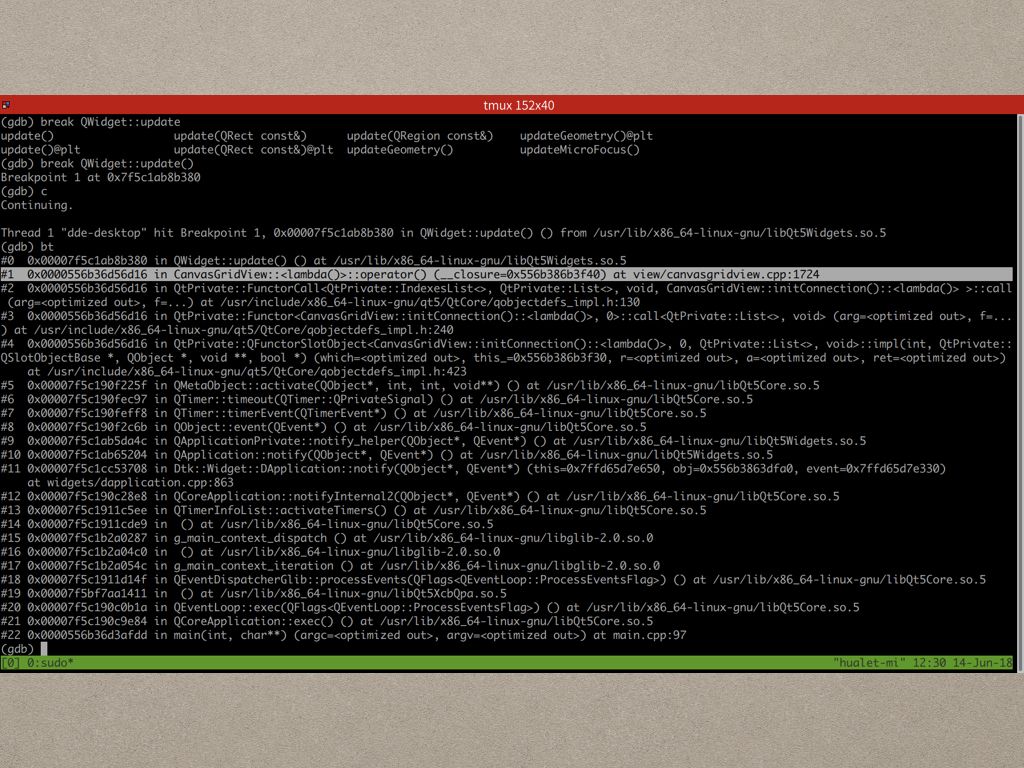
所以这个时候我们就得借助第三方工具,比如gdb,来帮助定位问题了,我们在QWidget::update上下个断点,发现有好几次都是图中高亮部分的调用导致了 CanvasGridView::update 的调用导致的多次重绘。
一看代码 https://github.com/linuxdeepin/dde-file-manager/blob/4.5.5/dde-desktop/view/canvasgridview.cpp ,可以发现就是有一个Timer在刷新,这个问题肯定是需要修复的啦。
演讲中又看了 startdde 和 dde-session-initializer 两个Go程序,因为有 runtime 和 deepin内部用的cgo的原因,定位稍微麻烦了一点,有时候需要借助gdb去catch syscall,这里就略过了。


修复了问题以后,我们自然需要验证是否优化成功了。
回归测试最好的办法正常情况下是编写测试用例,对有性能问题的函数进行单元测试和benchmark,这种方式最准确,但是我们实际上单元测试还比较少,这就需要我们的第二个工具了: funclatency-bpfcc,这个工具是bpfcc工具套件里面的一个工具,正常情况下也是用来看分析系统性能瓶颈的,这里我们可以用它来跟踪我们刚才优化过的函数,当然如果直接使用这个工具的话,粒度太粗了,我们真正优化的效果不一定能体现出来,如果真正使用就需要改进这个工具了。(讲的时候有个例子,这里略去)
下面两个工具就更不靠谱了,perf stat观察整个进程优化后的CPU时间占用:
Performance counter stats for 'system wide':
4913.197948 cpu-clock (msec) # 3.999 CPUs utilized
1,589 context-switches # 0.323 K/sec
92 cpu-migrations # 0.019 K/sec
4 page-faults # 0.001 K/sec
88,594,858 cycles # 0.018 GHz
40,904,994 instructions # 0.46 insn per cycle
8,961,552 branches # 1.824 M/sec
505,024 branch-misses # 5.64% of all branches
1.228484336 seconds time elapsed
其中我们最关心的就是 cpu-clock了。 当让下面那些指标对系统整体的性能诊断是非常有意义的,比如 context-switches、page-faults、 banches和branch-misses这些等等。
或者用 powertop 看看程序的整体能耗是不是从前十掉到后面了,这样就算优化非常有效了。
但是,就像前面说的这两种方式非常不靠谱,我们还是计量往正确的方向,也就是单元测试,前进吧。

最后就是考核了:
